一、过拟合无法避免,但可以量化
首先必须承认:在策略开发中,过拟合是不可避免的。 关键不在于“是否过拟合”,而在于——过拟合的程度有多大? 在我的经验中,系统性地估计过拟合程度,是实盘成功与否的分水岭。可惜的是,即便是顶尖量化对冲基金的研究员,对此也往往只有朴素的直觉。许多人仍把回测夏普率当作实盘表现的“真实值”,结果实盘大幅衰减,甚至亏损。 一些公司会采用经验法则,比如“实盘夏普率 ≈ 回测夏普率的 1/2 到 1/10”。这类规则虽粗糙,但至少体现了对过拟合的敬畏——这已经超越了多数人。 但在使用任何经验法则前,必须先排除两类低级错误: 数据问题:是否存在未来函数(look-ahead bias)? 方法论问题:参数是否用滚动窗口(rolling)校准?还是用全样本一次性拟合?后者本质上是错误的。 只有在确保这两点无误后,我们才能进入统计框架下的过拟合评估。 二、为什么夏普率是核心指标?
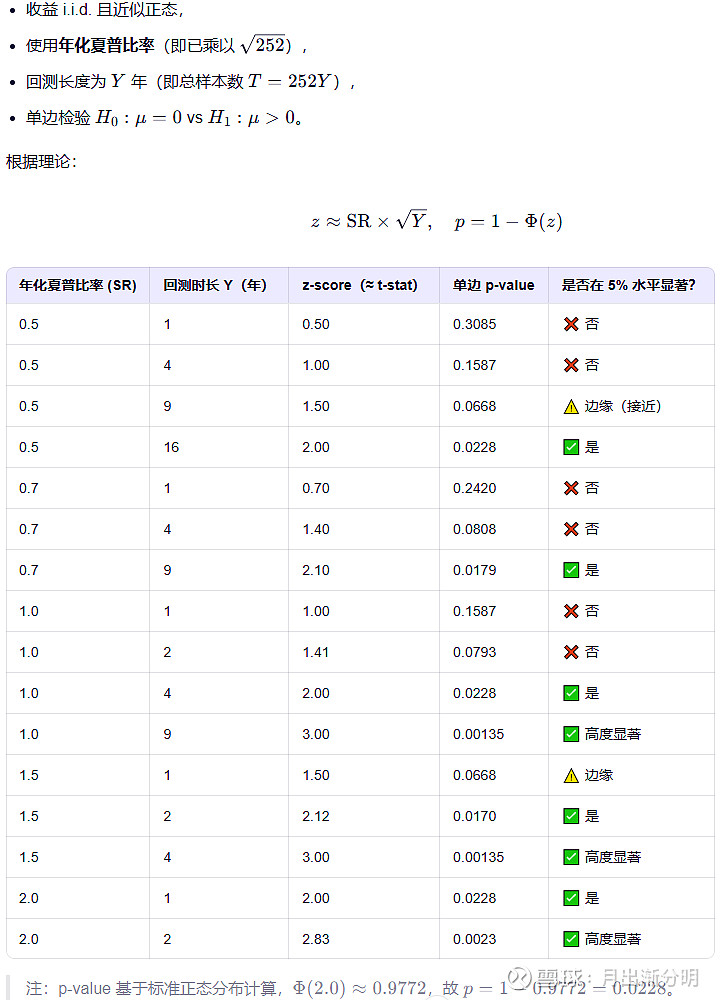
如果只能选一个指标衡量策略质量,那一定是夏普率(Sharpe Ratio)。 不是因为它直观,而是因为它的数学本质:夏普率直接衡量了策略的统计显著性(statistical significance)。 从统计学角度看,策略评估本质上是一个假设检验问题: H₀:策略的真实平均收益为零(即不能赚钱) H₁:策略的真实平均收益大于零 在独立同分布(i.i.d.)假设下,年化夏普率(SR)与回测年数(Y)共同决定了检验统计量。 表格:年化夏普比率(SR)与回测时长对统计显著性的影响,假设: 这个 z-score 直接对应 p-value。例如: SR = 1.0,回测 4 年 → z ≈ 2.0 → p ≈ 2.3%(显著) SR = 1.0,回测 1 年 → z ≈ 1.0 → p ≈ 16%(不显著) 因此,脱离回测长度谈夏普率是没有意义的。夏普率之所以强大,正是因为它编码了“信号强度”与“样本信息量”的联合信息。 三、过拟合 = 多重假设检验问题
当你在开发策略时反复尝试不同参数、模型、数据集,本质上是在进行多重假设检验(multiple testing)。 每一次尝试,都是一次对 H₀ 的检验。试得越多,偶然发现一个“高夏普”策略的概率就越高——即使所有策略都无效(H₀ 全为真)。 要量化这种“数据挖掘偏差”(data-mining bias),关键在于估计有效测试次数 n ——即“你到底试了多少次?” 如何估计 n?
网格搜索(Grid Search):直接用网格点数量作为 n 的上限。 连续参数优化:每个参数通常贡献 2–5 个“有效测试”(取决于模型对该参数的敏感度)。 为什么提前从1000只股票里面筛选100只和股票是不可行的?
再比如你预测1000个股票,选了100个效果最好的。那你的n还要乘 21000H2(0.1)2^{1000H_2(0.1)} 想象你在 1000 个按钮中选 100 个同时按下,只有某些组合能打开宝藏。 你试了一次“看起来最好的组合”就成功了——但你不知道的是,有 无数 种组合你没试,而随机按一个组合也有极小概率成功。 如果不校正这种“组合爆炸”,你就会把随机幸运当作真实信号。 四、Bonferroni 校正:从原始夏普到“实盘夏普”
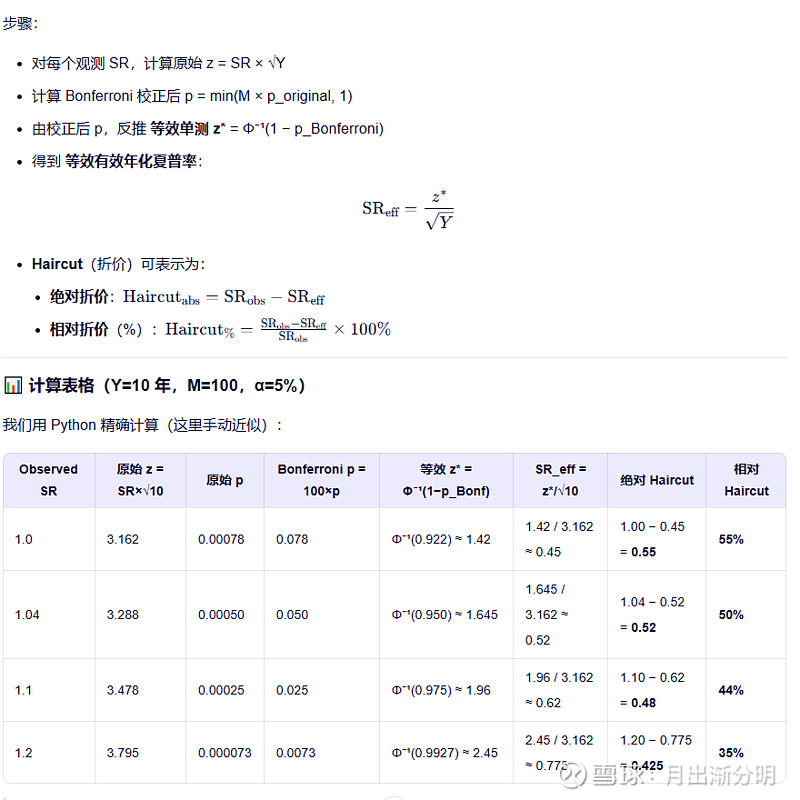
比如10年有100个测试结果大概夏普率在1.0-1.2之间,大概最后是怎么样的显著性,haircut(折价)sharp是多少?我们可以通过Bonferroni 校正算出结果: 注意:Bonferroni 是最保守的
(1)实际中,策略之间往往高度相关(如参数微调),并非 100 次独立测试。 (2)因此 Bonferroni 会过度惩罚,导致 haircut 被高估。 (3)更先进的方法如 Deflated Sharpe Ratio (DSR) 会考虑: 收益的偏度、峰度 回测长度 测试之间的相关性(有效独立测试数 < M) 但 Bonferroni 提供了一个安全下限:如果连它都通不过,策略大概率无效。 五、其他的回测校正方式对比
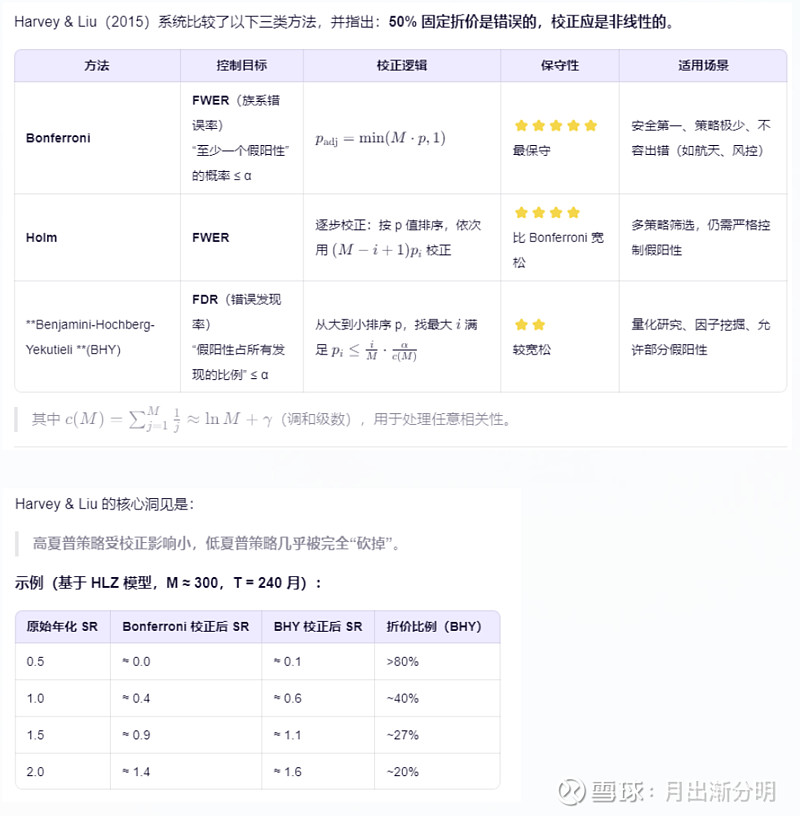
进一步考虑其他的校正方法:【Backtesting By Harvey & Liu(2015)】网页链接 T:回测样本长度(以“观测期数”为单位)
T = 240 月 表示策略回测了 240 个月,即 20 年(240 ÷ 12 = 20)。 它代表统计检验的有效样本量(number of observations)。 T 越大,同样夏普率对应的 t 值越高,统计显著性越强。 M:有效测试次数(effective number of tests)
M ≈ 300 表示在发现当前策略之前,大约已有 300 个类似策略(或因子)。 这个数字来自 HLZ 对学术文献的实证统计:截至 2015 年,至少有 316 个资产定价因子被提出并报告了显著结果。 M 并非指你个人试了多少次,而是整个研究共同体在相同数据集上进行的“相关”测试总数——因为你的策略也是在这个“因子宇宙”中被发现的。 六、“过拟合” 和 “策略周期性失效”
仅凭一个 1 年的观察期夏普率很低,不能断定策略过拟合;很可能只是运气不好,撞上了策略的“低谷周期”。 (1)策略的真实夏普率(true SR)是一个长期期望值,比如 1.2。 (2)但在有限样本(如 1 年)中,实现夏普率(realized SR)会因随机波动、市场状态而偏离真实值。 (3)尤其当策略依赖周期性风险溢价(如价值、动量、趋势)时,某些年份可能系统性表现差。 当 T=1 年,SR = 1.0 时,如果夏普率的标准差是1.22,这意味着:1 年实现夏普率有约 68% 概率落在 [-0.22, 2.22] 之间! 单年夏普率噪声极大,无法可靠推断策略好坏。 实际上,要有效区分真实策略与过拟合,样本外观察期的总长度应至少与样本内回测期相当。 例如,若回测使用5年数据,仅靠1年观察期难以得出可靠结论;需滚动积累5个独立的1年样本外表现,综合评估其夏普率的均值、稳定性及波动率,才能更合理地判断策略是否稳健。 这不仅要求PM具备较长的资金久期和较强的风险承受能力,也意味着策略需与其资金属性深度适配。 然而,现实中多数PM的考核周期仅为1年,这种短视激励机制容易导致策略设计趋于保守或过度拟合短期表现,反而限制了长期有效策略的实施空间。 七、“过拟合” 和 “策略失效”
最后强调一个关键区别: (1)过拟合(Overfitting):策略在样本内就是假阳性(false discovery),H₀ 实际为真。交易策略在样本内就是错的。 (2)策略失效(Regime Shift):策略在样本内真实有效(H₀ 被正确拒绝),但市场结构变化导致未来失效。而失效策略在样本内至少是正确的。 前者是统计错误,可通过多重检验校正控制; 后者是经济现实,需通过稳健性设计、动态适应来缓解
作者:月出渐分明
链接:https://xueqiu.com/6342158729/357193848
来源:雪球
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
风险提示:本文所提到的观点仅代表个人的意见,所涉及标的不作推荐,据此买卖,风险自负。
| 

 发表于 2025-12-24 21:34:44
发表于 2025-12-24 21:34:44